

Version
- 1.0 (02/2025)
Statut
Contexte du projet
Ce projet a été réalisé dans le cadre de la formation Développeur d’application Java proposée par OpenClassrooms. L’objectif était de créer le prototype d’une application médicale en adoptant une architecture microservices.
Le projet devait intégrer cinq microservices distincts : un pour l’interface utilisateur (front-end), un gateway pour rediriger les requêtes vers les services appropriés, un pour la gestion des patients, un pour la gestion des notes et un dernier pour la génération du rapport de risque de diabète.
Deux bases de données étaient requises : une SQL (respectant la norme NF3) pour stocker les informations des patients et une NoSQL dédiée aux notes des praticiens. Le rapport de risque de diabète était généré automatiquement à partir de déclencheurs (triggers) basés sur les notes des praticiens et les données des patients.
Enfin, l’ensemble de l’application devait être conteneurisé avec Docker, une technologie que j’ai découverte et utilisée pour la première fois dans ce projet.
Gallerie
Fonctionnalités
- Connexion : Permet à l’utilisateur de se connecter en tant qu’organisateur ou praticien.
Pour l’organisateur :
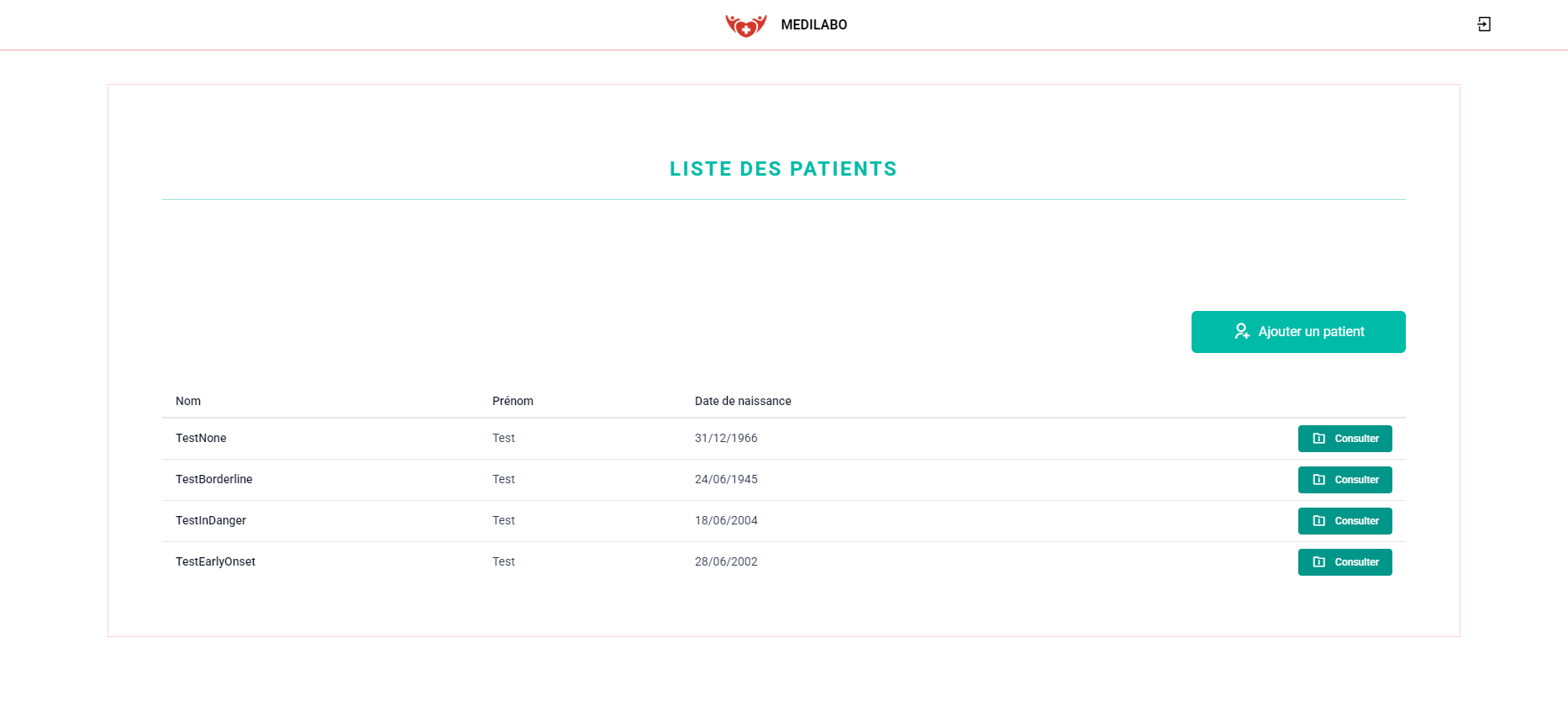
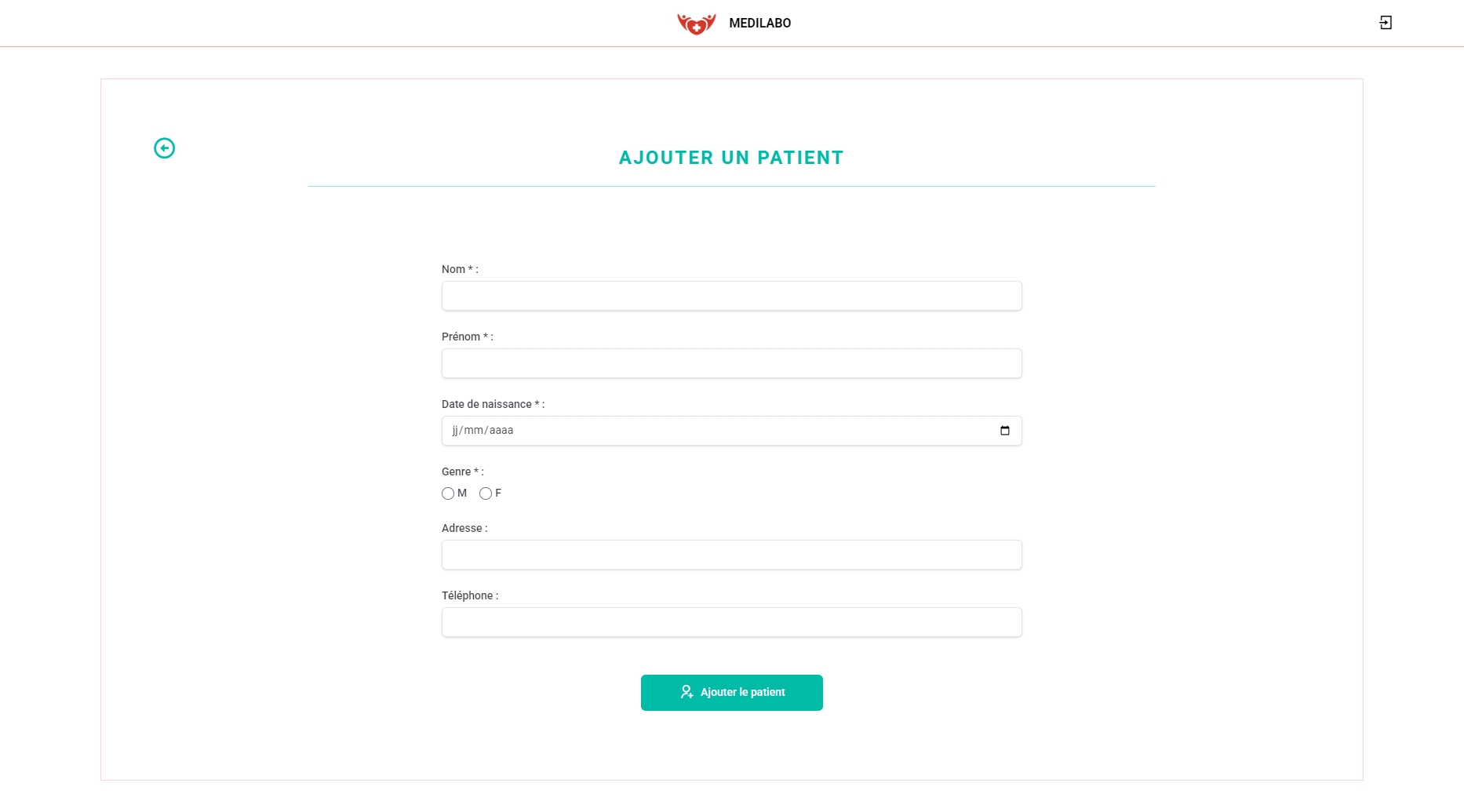
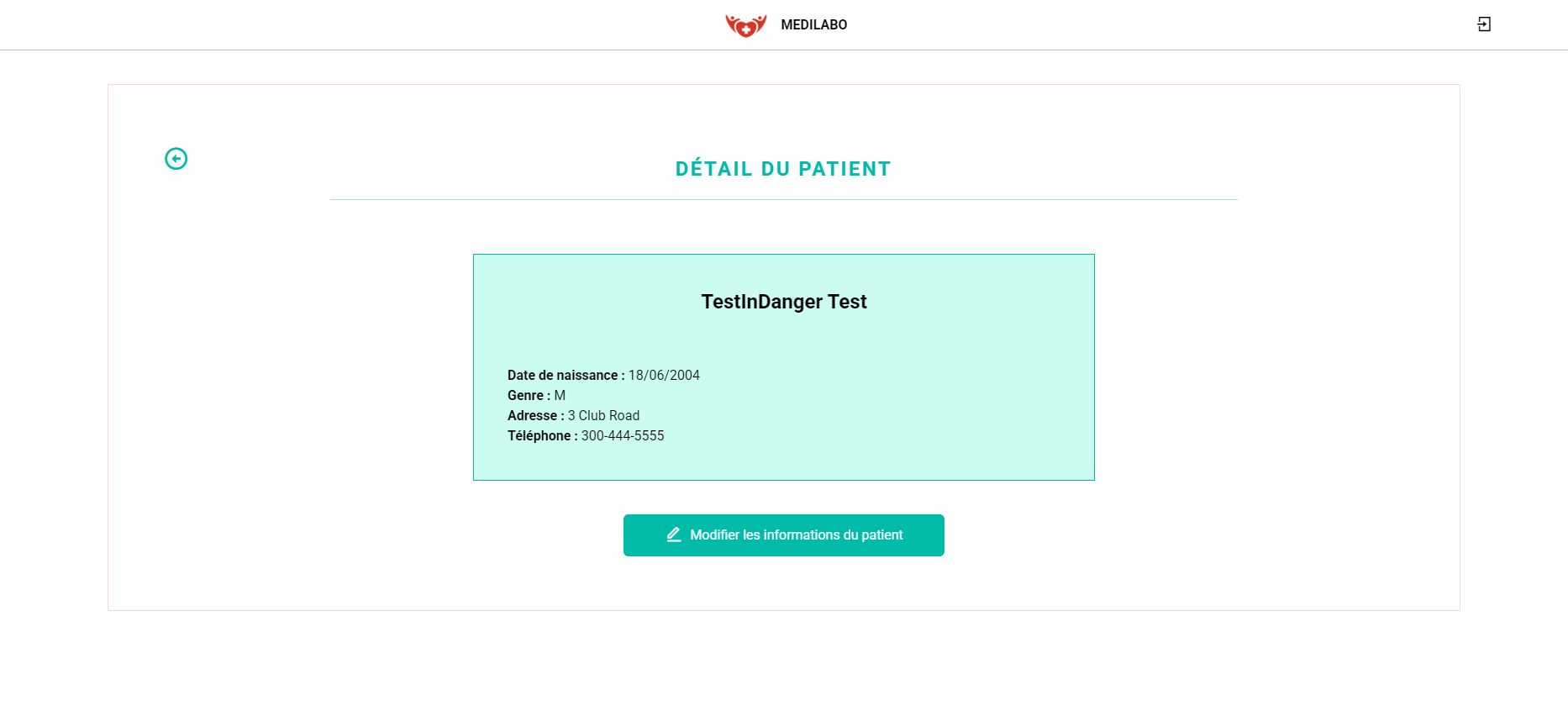
- Patients : Consultation, ajout et modification des informations des patients.
Pour le praticien :
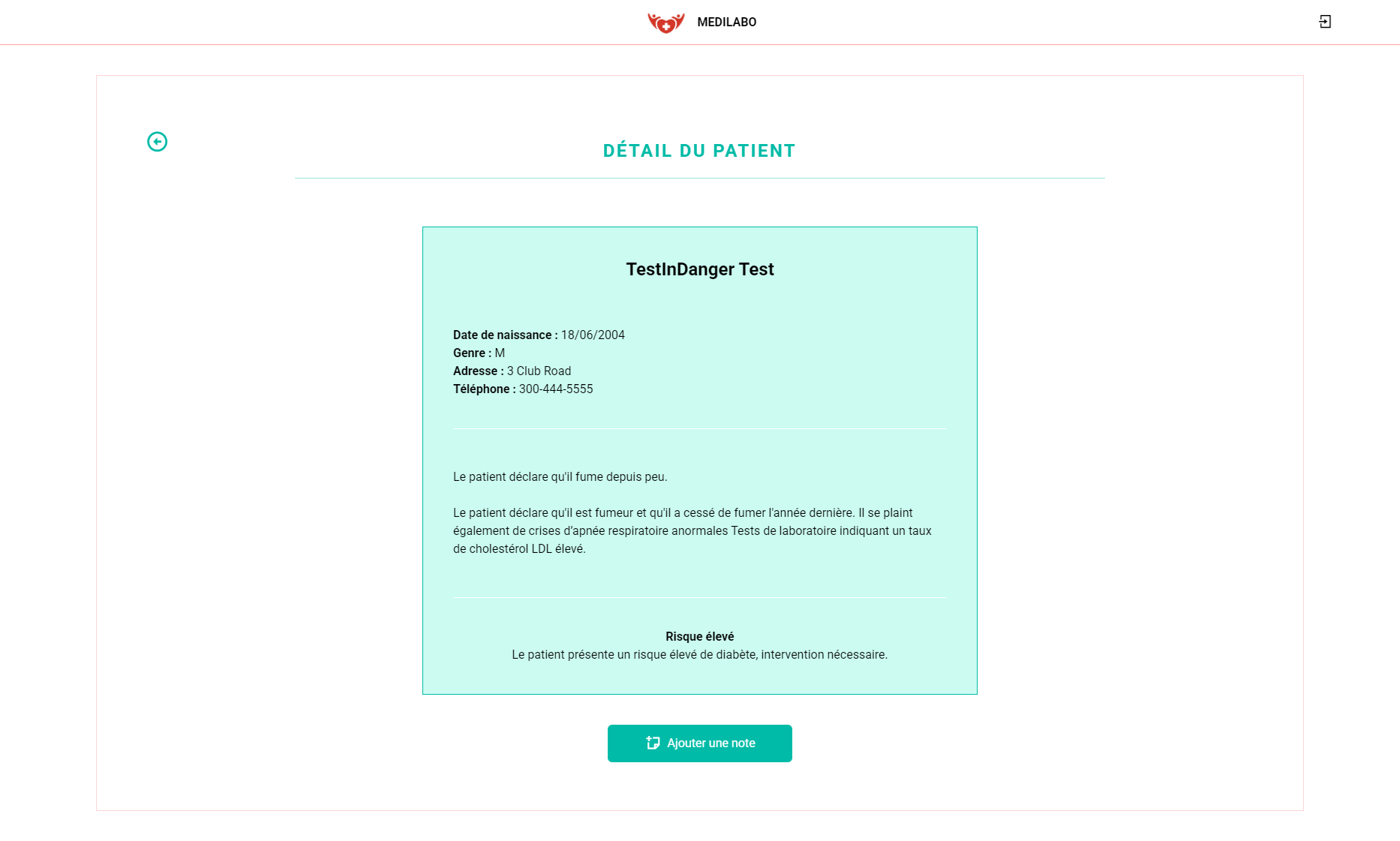
- Notes : Consultation et ajout de notes sur les patients.
- Rapport de risque de diabète : Consultation du rapport de risque de diabète pour un patient, généré à partir de triggers contenu dans les notes.
Stack Technique
Étant au cœur de la formation, l’usage de Java et Spring s’est imposé naturellement. Le choix de MongoDB pour la sauvegarde des notes médicales était contraint, mais parfaitement justifié : en tant que base NoSQL, il permet une grande flexibilité et une scalabilité horizontale, essentielles pour gérer des notes potentiellement volumineuses et évolutives.
En revanche, pour le stockage des informations des patients, il est primordial de garantir l’intégrité et la cohérence des données. Un système relationnel s’imposait donc, et PostgreSQL est apparu comme le choix le plus naturel. Réputé pour sa fiabilité et sa robustesse, il domine aujourd’hui le marché des bases de données open-source.
Côté interface, j’ai opté pour Tailwind CSS, un framework devenu incontournable pour accélérer le développement tout en offrant une grande flexibilité. Initialement, je souhaitais utiliser Angular pour ce projet, mais faute de temps pour un apprentissage approfondi, j’ai préféré m’appuyer sur une technologie que je maîtrise déjà : Thymeleaf, le moteur de rendu natif de Spring Boot.
Architecture
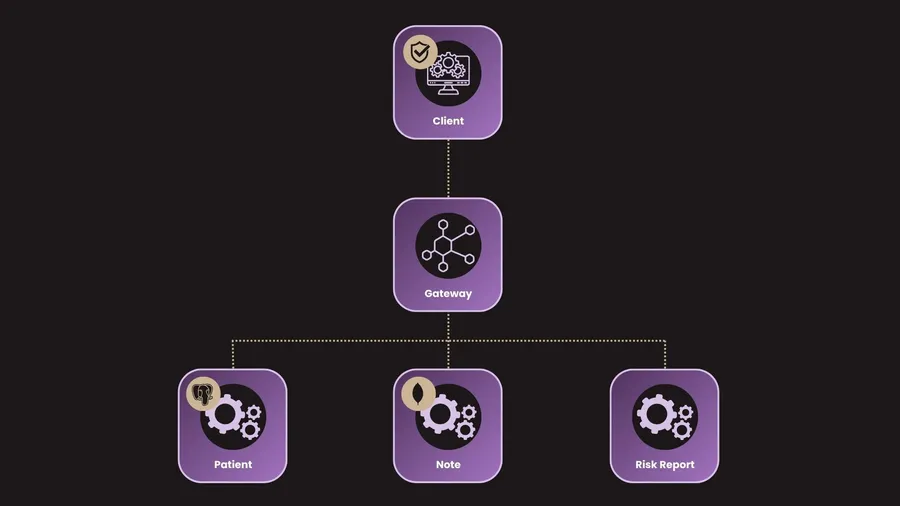
L’architecture du projet repose sur plusieurs microservices spécialisés, chacun ayant un rôle bien défini :
- Microservice Client : Fournit l’interface utilisateur et sert de point d’entrée pour l’application. Il gère également la sécurité (authentification et autorisation), bien que cette tâche soit généralement dévolue à la gateway lorsque le client est basé sur un framework front-end comme Angular ou React.
- Microservice Gateway : Assure la communication entre les différents microservices. Il reçoit les requêtes du client et les achemine vers le service backend approprié.
- Microservice Patient : Responsable de la gestion des informations relatives aux patients. Il interagit avec une base de données PostgreSQL pour stocker et manipuler ces données.
- Microservice Note : Gère les annotations des praticiens concernant les patients. Il s’appuie sur une base de données NoSQL MongoDB, idéale pour stocker des données non structurées et évolutives.
- Microservice Risk Report : Analyse les données issues des notes médicales et des informations personnelles des patients afin d’évaluer le risque de diabète en fonction de critères spécifiques.
Focus sur la gestion du risque de diabète
Pour l’évaluation du risque de diabète, plusieurs consignes ont été définies, notamment :
- Les niveaux de dangerosité possibles.
- Les règles de classification permettant de déterminer le niveau de risque d’un patient en fonction de ses données médicales.
Le risque est classé en quatre niveaux :
- Aucun risque (None) : Le patient ne présente aucun facteur détecté.
- Risque limité (Borderline) : Quelques facteurs sont présents, mais sans danger immédiat.
- Danger (In Danger) : La probabilité d’un développement du diabète est élevée.
- Apparition précoce (Early onset) : Le risque est critique, avec des signes avant-coureurs forts.
Les règles d’évaluation :
- Aucun risque (None) : Le dossier du patient ne contient aucune note du médecin contenant les déclencheurs (terminologie).
- Risque limité (Borderline) : Le dossier du patient contient entre deux et cinq déclencheurs et le patient est âgé de plus de 30 ans.
- Danger (In Danger) : Dépend de l’âge et du sexe du patient. Si le patient est un homme de moins de 30 ans, alors trois termes déclencheurs doivent être présents. Si le patient est une femme et a moins de 30 ans, il faudra quatre termes déclencheurs. Si le patient a plus de 30 ans, alors il en faudra six ou sept.
- Apparition précoce (Early onset) : Encore une fois, cela dépend de l’âge et du sexe. Si le patient est un homme de moins de 30 ans, alors au moins cinq termes déclencheurs sont nécessaires. Si le patient est une femme et a moins de 30 ans, il faudra au moins sept termes déclencheurs. Si le patient a plus de 30 ans, alors il en faudra huit ou plus.
Définition des règles d’évaluation
Étant donné la complexité des conditions et afin d’assurer une solution maintenable et lisible, j’ai opté pour l’utilisation de deux énumérations (enum). La première consiste à définir des valeurs qui vont contenir le label et la description pour chaque niveau de dangerosité et qui seront renvoyées au client.
public enum RiskLevel {
NONE("Aucun risque", "Le patient ne présente aucun risque de diabète."),
BORDERLINE("Risque limité", "Le patient présente un risque limité de diabète, mais une surveillance est nécessaire."),
EARLY_ONSET("Apparition précoce", "Le patient présente des signes d'apparition précoce de diabète."),
IN_DANGER("Risque élevé", "Le patient présente un risque élevé de diabète, intervention nécessaire.");
private final String label;
private final String description;
RiskLevel(String label, String description) {
this.label = label;
this.description = description;
}
}La seconde énumération est chargée de définir les différents cas mentionnés dans les règles. Elle prend en compte :
- Le nombre d’occurrences des termes déclencheurs dans les notes (valeurs minimales et maximales).
- L’âge du patient.
- Le genre du patient.
- Le niveau de dangerosité correspondant, c’est-à-dire une valeur issue de la première énumération.
public enum RiskLevelThreshold {
BORDERLINE(2, 5, 30, null, RiskLevel.BORDERLINE), // Risque limité pour adultes (peu importe le genre)
EARLY_ONSET_MALE(5, Integer.MAX_VALUE, 0, "M", RiskLevel.EARLY_ONSET), // Risque d'apparition précoce pour les hommes
EARLY_ONSET_FEMALE(7, Integer.MAX_VALUE, 0, "F", RiskLevel.EARLY_ONSET), // Risque d'apparition précoce pour les femmes
EARLY_ONSET_ADULT(8, Integer.MAX_VALUE, 30, null, RiskLevel.EARLY_ONSET), // Risque d'apparition précoce pour les adultes
IN_DANGER_MALE(3, Integer.MAX_VALUE, 0, "M", RiskLevel.IN_DANGER), // Risque pour les hommes
IN_DANGER_FEMALE(4, Integer.MAX_VALUE, 0, "F", RiskLevel.IN_DANGER), // Risque pour les femmes
IN_DANGER_ADULT(6, 7, 30, null, RiskLevel.IN_DANGER); // Risque pour les adultes
private final Logger logger = LoggerFactory.getLogger(RiskReportService.class);
private final int minTriggers;
private final int maxTriggers;
private final int minAge;
private final String gender; // "M", "F" ou null si applicable à tous
@Getter
private final RiskLevel riskLevel;
RiskLevelThreshold(int minTriggers, int maxTriggers, int minAge, String gender, RiskLevel riskLevel) {
this.minTriggers = minTriggers;
this.maxTriggers = maxTriggers;
this.minAge = minAge;
this.gender = gender;
this.riskLevel = riskLevel;
}
}Méthode matches : Évaluation du cas du patient
Dans cette même énumération, j’ai créé une méthode matches permettant d’évaluer la situation d’un patient. Cette méthode prend en paramètres :
- L’âge du patient.
- Le nombre d’occurrences des déclencheurs dans les notes.
- Le genre du patient.
Grâce à ces informations, plusieurs conditions sont évaluées pour déterminer le niveau de risque approprié.
public boolean matches(int age, long triggerCount, String gender) {
boolean genderMatches = this.gender == null || this.gender.equalsIgnoreCase(gender);
boolean triggersMatch = (triggerCount >= this.minTriggers && triggerCount <= this.maxTriggers);
boolean ageMatch = (age >= this.minAge);
return genderMatches && triggersMatch && ageMatch;
}Grâce à cette approche basée sur les énumérations, le code principal est beaucoup plus concis et facilement maintenable par rapport à une structure classique en if/else imbriqués. En cas d’ajout de nouvelles règles ou de modifications, il suffit de modifier les énumérations, sans toucher au code principal.
Calcul du risque de diabète
private RiskLevel calculateRiskLevel(PatientDTO patient, int triggerCount) {
int age = DateUtil.calculateAge(patient.birthdate());
String gender = patient.gender();
if (triggerCount == 0) return RiskLevel.NONE;
return Arrays.stream(RiskLevelThreshold.values())
.filter(threshold -> threshold.matches(age, triggerCount, gender))
.findFirst()
.map(RiskLevelThreshold::getRiskLevel)
.orElse(RiskLevel.NONE);
}La méthode calculateRiskLevel est au cœur du calcul du risque. Elle prend en paramètres un patient et le nombre d’occurrences des déclencheurs dans les notes. Son rôle est simple : analyser ces données pour déterminer le niveau de risque le plus adapté.
Tout d’abord, l’âge du patient est calculé à partir de sa date de naissance grâce à DateUtil.calculateAge(), et son genre est récupéré. Si aucune occurrence de déclencheur n’est détectée (triggerCount == 0), il est inutile de poursuivre le traitement : le niveau de risque renvoyé est immédiatement NONE, évitant ainsi un calcul superflu et optimisant les performances.
Si des occurrences sont présentes, la méthode parcourt l’énumération RiskLevelThreshold, qui contient les différentes règles d’évaluation. Chaque élément est comparé avec le profil du patient à l’aide de la méthode matches() détaillé plus haut. Dès qu’une correspondance est trouvée, le niveau de risque correspondant est retourné. Si aucune règle ne s’applique, le système considère par défaut que le patient ne présente aucun risque et renvoie NONE.
Dockerisation de l’application
Ce projet a été l’occasion de découvrir Docker et de l’intégrer en fin de développement. J’ai opté pour une approche proche d’un environnement de production, bien que simplifiée : pas de proxy ou reverse proxy, et une gestion minimale des aspects liés à la sécurité.
Dockerfile
La première étape a été de rédiger un Dockerfile pour chaque microservice. Tous suivent une structure similaire, à l’exception du client, où l’installation de TailwindCSS devait être prise en compte.
Voici un Dockerfile type utilisé pour les microservices back-end :
# Build avec JDK et Gradle
FROM eclipse-temurin:21-jdk-alpine AS builder
WORKDIR /app
# Copie les fichiers Gradle et le code source
COPY . .
# Construit l’application avec Gradle
RUN ./gradlew build --no-daemon
# Étape 2: Exécution avec une image plus légère (JRE uniquement)
FROM eclipse-temurin:21-jre-alpine
WORKDIR /app
# Copie l’application construite depuis l’étape de build
COPY --from=builder /app/build/libs/*.jar app.jar
# Lance l’application avec optimisation mémoire
ENTRYPOINT ["java", "-jar", "app.jar"]Afin de réduire la taille de l’image Docker, j’ai mis en place un build multi-étapes.
- Première étape (builder)
- On utilise une image officielle Docker contenant le JDK (Java Development Kit) pour compiler l’application.
- L’environnement de travail est défini dans
/app. - Tous les fichiers du projet sont copiés dans l’image.
- L’application est buildée avec Gradle (
./gradlew build --no-daemon).
- Seconde étape (exécution optimisée)
- Ici, on utilise une image plus légère qui contient uniquement la JRE (Java Runtime Environment), suffisante pour exécuter l’application.
- Seul le fichier
.jargénéré dans l’étape précédente est copié dans cette nouvelle image. - L’application est démarrée avec
java -jar app.jardéfini viaENTRYPOINT.
- Images plus légères : En séparant le build et l’exécution, l’image finale ne contient que l’essentiel.
- Optimisation des performances : La JRE seule est plus rapide et consomme moins de ressources qu’une image avec le JDK complet.
- Meilleure modularité : Cette approche peut être appliquée à tous les microservices de manière uniforme.
L’intégration de Docker permet ainsi de standardiser le déploiement, d’améliorer la portabilité et d’assurer une exécution cohérente sur différents environnements.
Docker Compose
Une fois tous les Dockerfiles définis pour chaque microservice, il est temps de passer à la rédaction du fichier docker-compose.yml. Celui-ci permet de déployer et orchestrer facilement l’ensemble des conteneurs nécessaires à l’application.
Pour cela, plusieurs services Docker doivent être déclarés, notamment :
- Le client (interface utilisateur),
- La gateway (point d’entrée pour la communication entre services),
- Les microservices métier (gestion des patients, des notes, etc.),
- Les bases de données nécessaires (PostgreSQL, MongoDB).
Voici le fichier complet :
services:
client:
build:
context: ./client-service
dockerfile: Dockerfile
restart: unless-stopped
networks:
- frontend_network
ports:
- "8081:8081"
depends_on:
- gateway
environment:
TZ: Europe/Paris
gateway:
build:
context: ./gateway-service
dockerfile: Dockerfile
restart: unless-stopped
networks:
- frontend_network
- backend_network
depends_on:
- patient
- note
- risk-report
environment:
TZ: Europe/Paris
patient:
build:
context: ./patient-service
dockerfile: Dockerfile
restart: unless-stopped
networks:
- backend_network
depends_on:
- patient-db
env_file: .env
environment:
SPRING_DATASOURCE_URL: jdbc:postgresql://patient-db:5432/${POSTGRES_DB}
SPRING_DATASOURCE_USERNAME: ${POSTGRES_USER}
SPRING_DATASOURCE_PASSWORD: ${POSTGRES_PASSWORD}
TZ: Europe/Paris
patient-db:
image: postgres:16
restart: unless-stopped
networks:
- backend_network
env_file: .env
environment:
POSTGRES_DB: ${POSTGRES_DB}
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
TZ: Europe/Paris
volumes:
- postgres_data:/var/lib/postgresql/data
note:
build:
context: ./note-service
dockerfile: Dockerfile
restart: unless-stopped
networks:
- backend_network
depends_on:
- note-db
environment:
SPRING_DATA_MONGODB_HOST: note-db
SPRING_DATA_MONGODB_PORT: 27017
SPRING_DATA_MONGODB_DATABASE: medilabo
TZ: Europe/Paris
note-db:
image: mongo:7
restart: unless-stopped
networks:
- backend_network
volumes:
- mongo_data:/data/db
- ./note-service/initdb:/docker-entrypoint-initdb.d:ro
environment:
MONGO_INITDB_DATABASE: medilabo
TZ: Europe/Paris
risk-report:
build:
context: ./risk-report-service
dockerfile: Dockerfile
restart: unless-stopped
networks:
- backend_network
depends_on:
- patient
- note
environment:
TZ: Europe/Paris
volumes:
postgres_data:
mongo_data:
networks:
frontend_network:
backend_network:Définition du service client dans le Docker Compose
client:
build:
context: ./client-service
dockerfile: Dockerfile
restart: unless-stopped
networks:
- frontend_network
ports:
- "8081:8081"
depends_on:
- gateway
environment:
TZ: Europe/ParisDécryptons les différentes options utilisées ici :
- Nom du service : le service est déclaré sous le nom client, ce qui permettra à Docker Compose de le gérer sous cette appellation.
- Construction de l’image : l’option build précise l’image Docker à utiliser, en indiquant :
- Le contexte (
context: ./client-service), c’est-à-dire l’emplacement du projet. - Le Dockerfile (
dockerfile: Dockerfile) qui contient les instructions de build.
- Le contexte (
- Redémarrage automatique : l’option
restart: unless-stoppedgarantit que le conteneur sera toujours redémarré en cas de crash ou de redémarrage du système, sauf si on l’arrête manuellement. - Gestion du réseau : le service client est affecté à un network spécifique (
frontend_network), ce qui joue un rôle clé dans l’isolement des communications.
Dans cette architecture, le client ne doit pas communiquer directement avec les services back-end. Il est donc exclusivement connecté à la gateway, qui servira d’intermédiaire entre le frontend et le backend. La gateway, elle, sera connectée aux deux networks : frontend_network et backend_network, assurant ainsi la liaison entre les parties visibles et internes de l’application. Cette séparation améliore la sécurité, car aucun microservice backend n’est accessible directement depuis l’extérieur.
-
Exposition des ports : le client est mappé sur le port 8081 (
ports: "8081:8081"), ce qui signifie :- Il sera accessible depuis l’extérieur via
http://localhost:8081. - Il s’agit du seul service à exposer un port sur l’hôte, car nous ne voulons pas que les autres microservices soient accessibles publiquement.
- Il sera accessible depuis l’extérieur via
-
Dépendance au service gateway : l’option
depends_on: gatewayindique que le client ne sera lancé qu’une fois la gateway démarrée. C’est essentiel, car toutes les requêtes frontend passent par cette dernière.
Chaque microservice suit globalement la même logique, avec quelques variations :
- Les dépendances (
depends_on) varient en fonction des services dont ils ont besoin. - Les networks sont configurés en conséquence pour garantir un bon cloisonnement.
- Les bases de données, en revanche, nécessitent une approche légèrement différente, car elles doivent conserver les données même après un redémarrage.
Définition du service patient-db dans le Docker Compose
La configuration d’une base de données nécessite quelques précautions particulières. Voici comment est défini le service patient-db dans le fichier docker-compose.yml :
patient-db:
image: postgres:16
restart: unless-stopped
networks:
- backend_network
env_file: .env
environment:
POSTGRES_DB: ${POSTGRES_DB}
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
TZ: Europe/Paris
volumes:
- postgres_data:/var/lib/postgresql/data-
Utilisation d’une image préexistante : contrairement aux microservices qui nécessitent un build personnalisé, la base de données utilise directement l’image officielle de PostgreSQL (
postgres:16). -
Gestion des variables d’environnement : l’authentification et les paramètres de connexion sont définis via un fichier
.env(env_file: .env), qui contient :
POSTGRES_DB=mydatabase
POSTGRES_USER=myuser
POSTGRES_PASSWORD=mypasswordLes informations sensibles (mot de passe, utilisateur) doivent être stockées en dehors du docker-compose.yml pour éviter qu’elles ne soient visibles ou versionnées dans un dépôt Git. Le fichier .env est chargé automatiquement et injecte les valeurs dynamiquement grâce à la syntaxe ${VARIABLE}.
- Utilisation d’un volume pour la persistance des données : le volume
postgres_data(volumes: - postgres_data:/var/lib/postgresql/data) permet de conserver les données même si le conteneur est arrêté ou supprimé. Sans ce volume, la base serait réinitialisée à chaque redémarrage, ce qui effacerait toutes les données enregistrées.