


Version
- 0.1.0 (09/2024)
Statut
Contexte du projet
Ce projet figure parmi les huit réalisations pratiques de la formation Développeur d’application Java proposée par OpenClassrooms. L’objectif était de concevoir un prototype d’application de transfert d’argent entre amis de A à Z, en respectant les spécifications fonctionnelles et techniques fournies.
Le but principal de cette mission était de solidifier mes compétences avec le framework Spring, en particulier à travers l’utilisation de Spring Data pour gérer les interactions avec la base de données de manière efficace et performante. Parallèlement, j’ai utilisé le moteur de rendu Thymeleaf pour permettre la génération dynamique des pages web et créer une interface utilisateur simple et fonctionnelle.
Gallerie

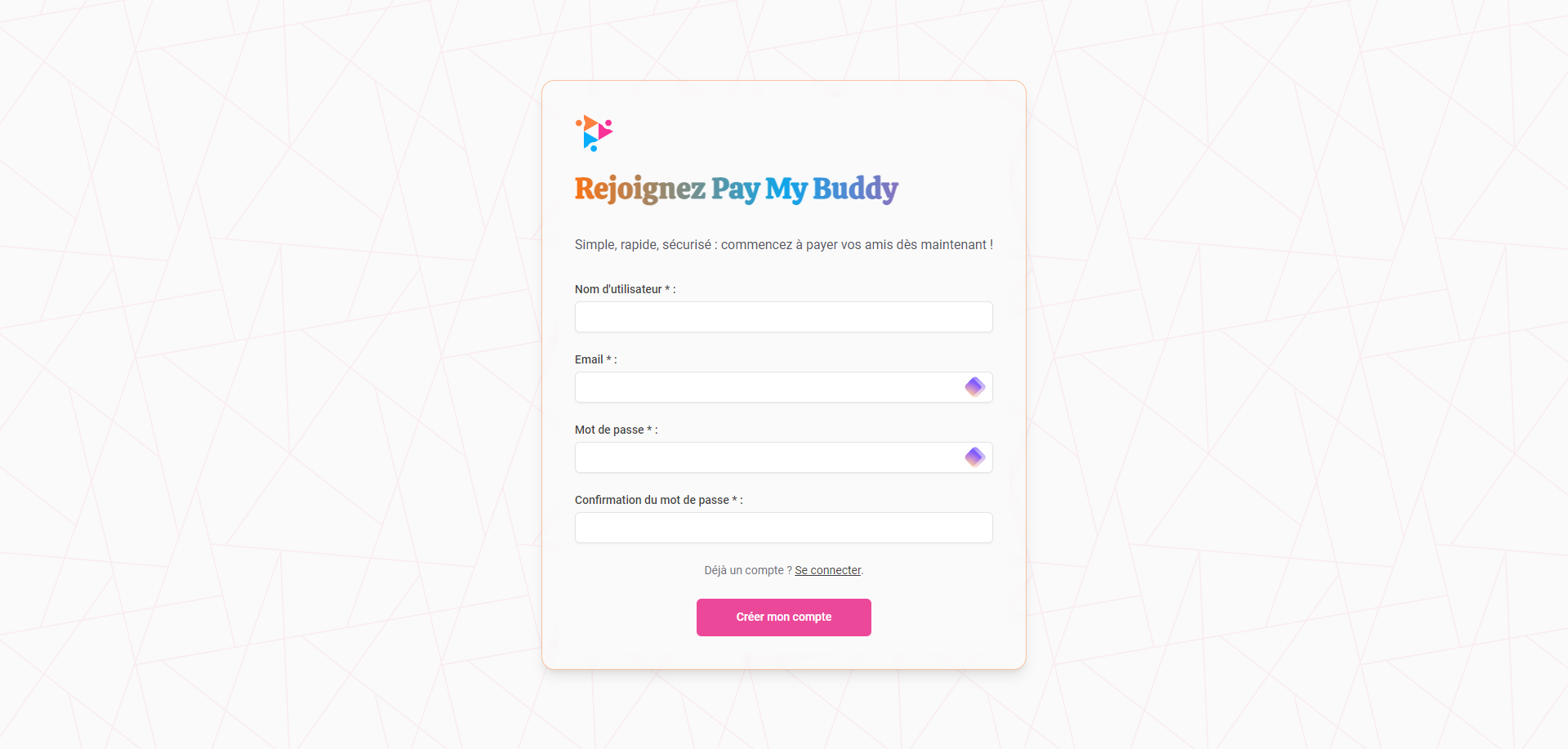
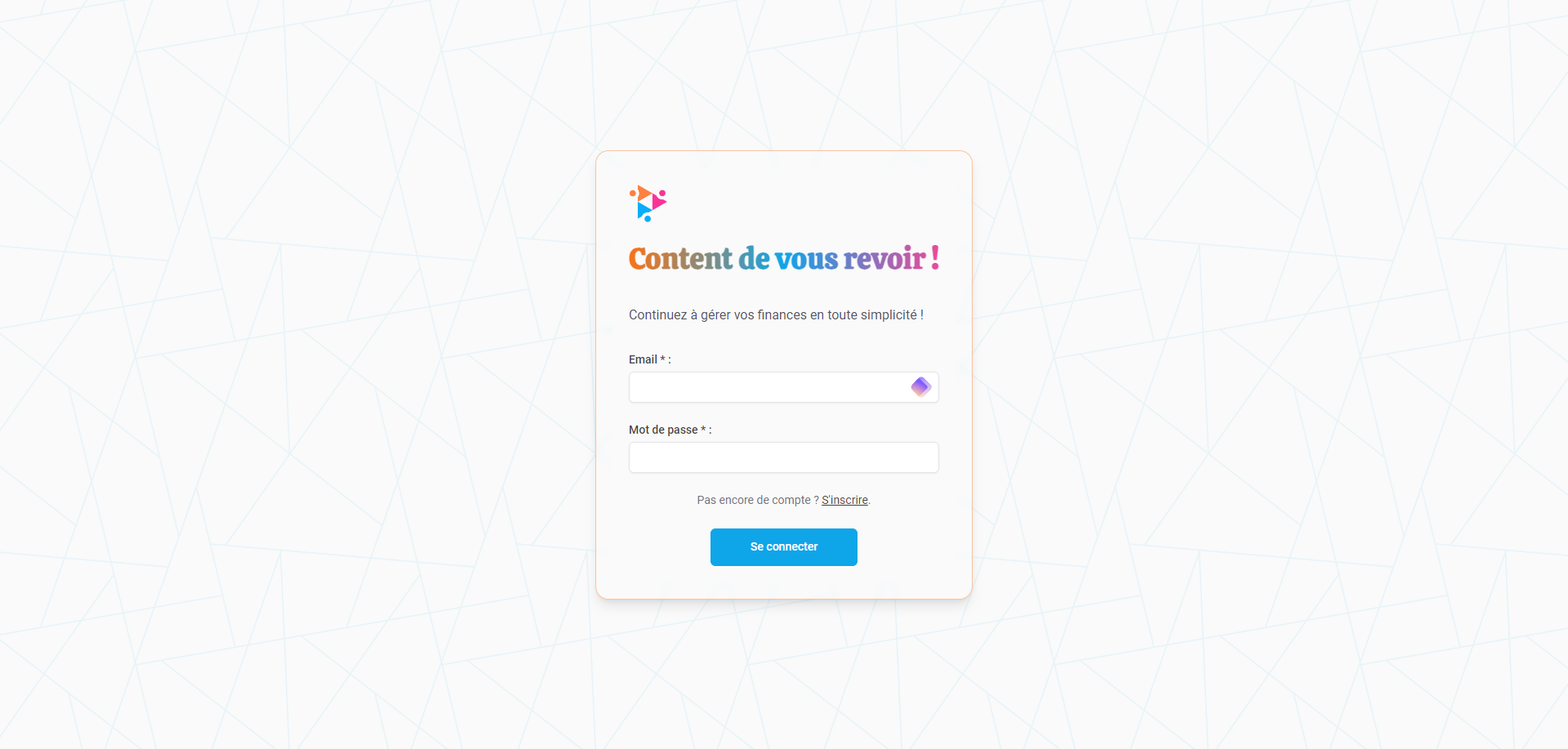
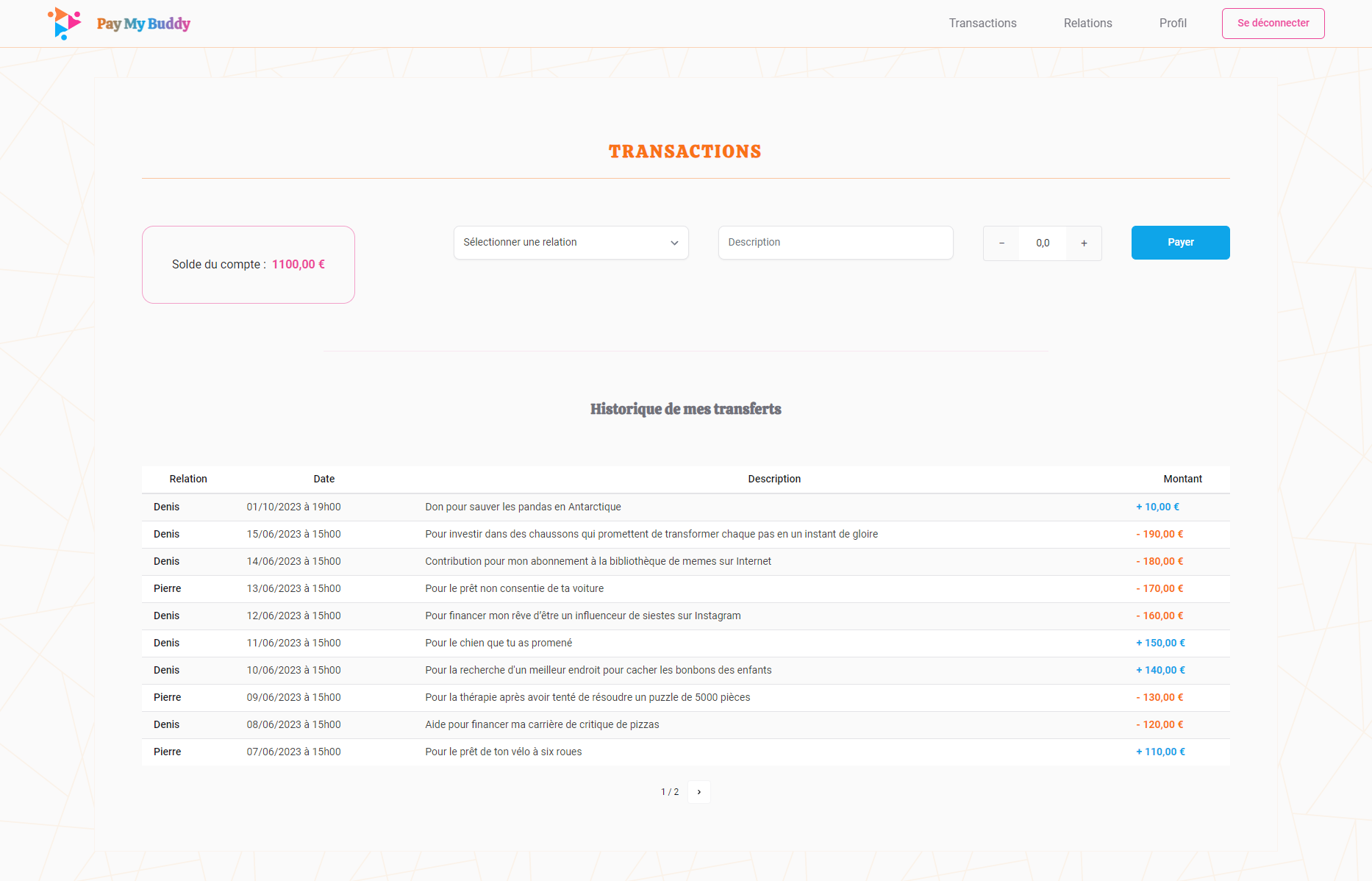
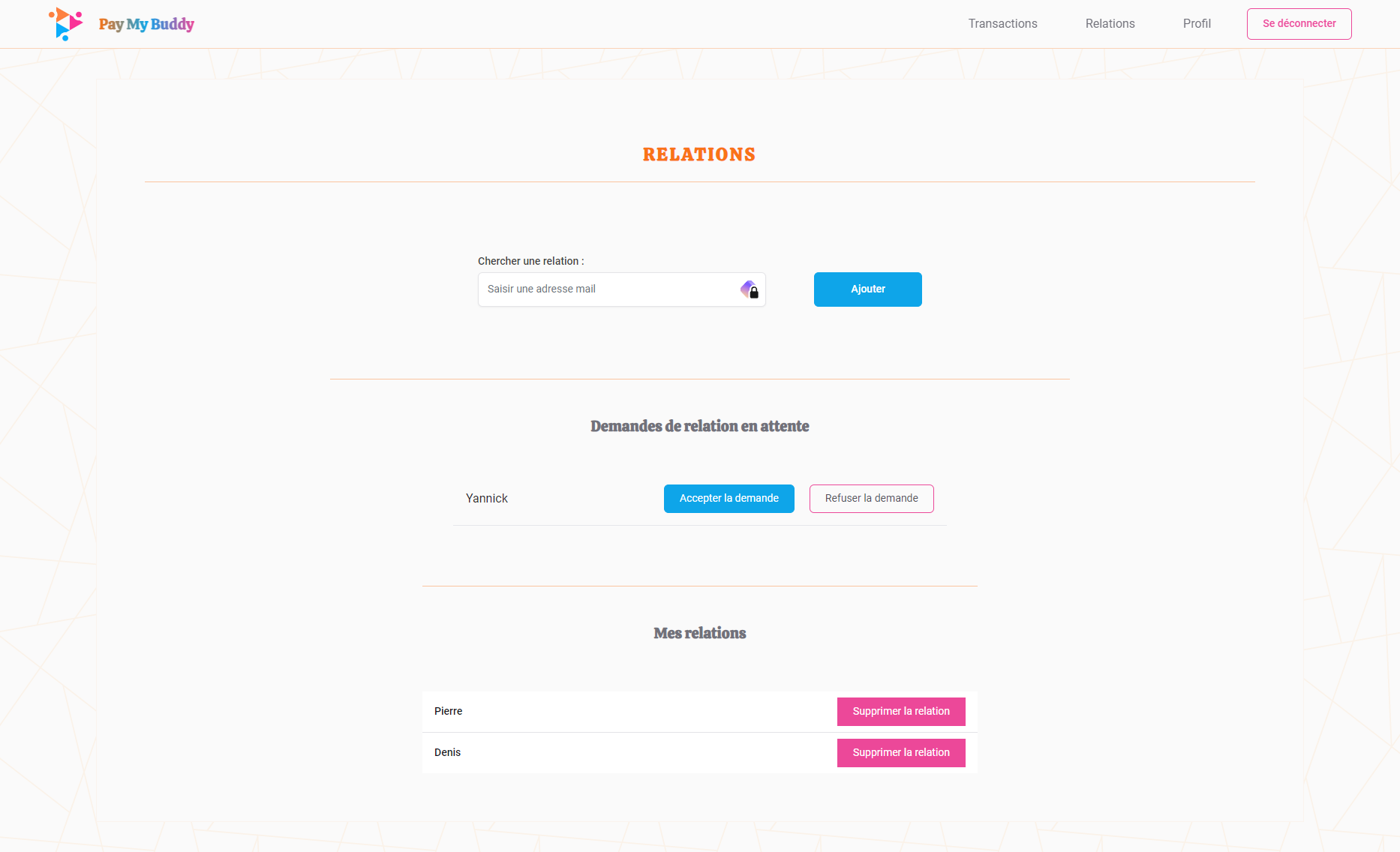

Fonctionnalités
- Inscription et connexion : Permet à l’utilisateur de créer un compte et de se connecter.
- Gestion du profil : L’utilisateur peut modifier ses informations personnelles via son profil.
- Gestion des relations : Ajout, validation et suppression des relations entre utilisateurs.
- Transfert d’argent : Possibilité d’envoyer de l’argent à d’autres utilisateurs.
- Historique des transactions : Consultation des transactions financières effectuées.
Stack Technique
En dehors du langage Java, associé au framework populaire Spring, et de l’usage de Thymeleaf pour le rendu côté serveur, j’avais carte blanche pour choisir la stack technique concernant l’outil de build, la gestion de l’interface utilisateur, et le système de gestion de base de données.
Ayant une expérience préalable avec Maven, j’ai choisi d’utiliser Gradle pour ce projet. Bien qu’il nécessite plus de configuration initiale, son système de gestion des dépendances est à la fois plus clair et plus flexible. Je trouve personnellement que la syntaxe en Kotlin est plus lisible qu’un fichier XML.
Pour la base de données, j’ai opté pour PostgreSQL, une solution reconnue pour ses fonctionnalités avancées comme le support des types de données complexes et la gestion fine des transactions. Ce projet a été l’occasion de sortir de ma zone de confort, en abandonnant MySQL pour un système qui est désormais une référence dans le domaine des bases de données relationnelles.
Enfin, pour le développement de l’interface utilisateur, j’ai utilisé Tailwind CSS, un framework basé sur des classes utilitaires. Il m’a permis de construire des interfaces rapidement, sans avoir à écrire de CSS personnalisé.
Organisation du code
L’organisation suit le modèle MVC (Modèle-Vue-Contrôleur) pour garantir une séparation claire des responsabilités et une maintenabilité optimale du code. La structure du projet est la suivante :
| Nom du package | Responsabilité |
|---|---|
| Config | Centralise les configurations de l'application. |
| Controller | Gère les requêtes HTTP et la vue Thymeleaf à renvoyer. |
| Service | Contient la logique métier de l'application. |
| Repository | Gère les interactions avec la base de données. |
| DTO | Contient les objets de transfert de données utilisés pour transporter des informations entre les différentes couches de l'application sans exposer directement les entités du modèle. Le package comprends aussi les Projections SQL. |
| Model | Définit les entités et objets métiers utilisés dans l'application. |
| Exception | Centralise la gestion des erreurs et des exceptions. |
| Util | Regroupe des fonctions utilitaires et des classes d'assistance pour le hashage du mot de passe et la gestion de session afin d'éviter la duplication de code et améliorer la réutilisabilité. |
En parallèle, un dossier resources contient les vues Thymeleaf, les fichiers de configuration et les fichiers statiques (images, CSS, etc.).
Structure de la base de données
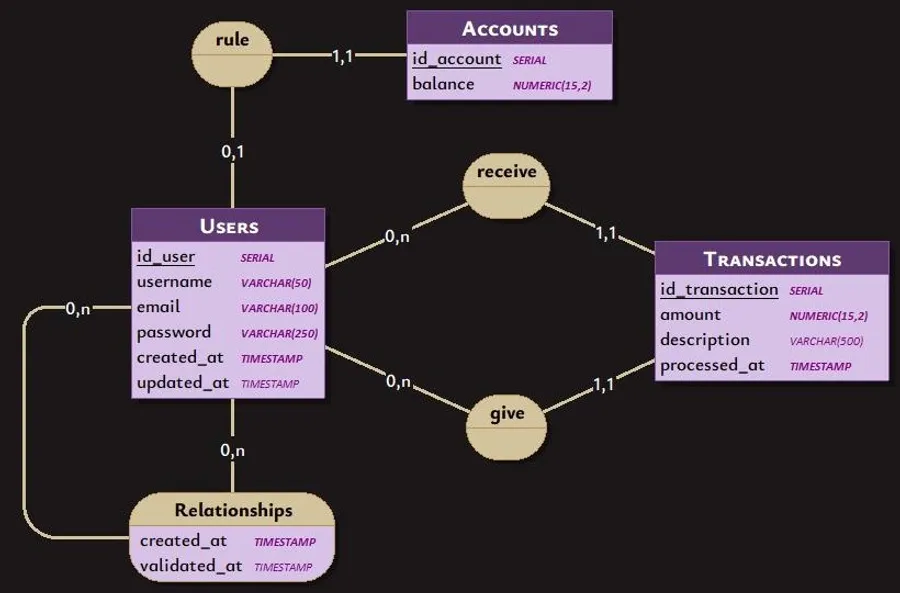
Plusieurs précautions ont été prises lors de l’élaboration du script SQL. Outre le typage habituel des colonnes, des valeurs par défaut ont été définies chaque fois que possible pour alléger la charge de travail du code Java. Par exemple, la date de création d’un utilisateur est automatiquement renseignée lors de l’insertion d’un nouvel utilisateur, ce qui évite de devoir gérer cette tâche dans le code applicatif.
L’intégrité des données est garantie par l’utilisation de contraintes d’intégrité référentielle, ce qui assure la cohérence des données entre les différentes tables. Par exemple, la suppression d’un utilisateur entraîne la suppression de ses relations et de son compte associé, mais pas de ses transactions. Celles-ci sont anonymisées pour conserver un historique intact pour l’autre utilisateur.
Par ailleurs, certaines données sont rendues obligatoires (comme le champ password) ou uniques (comme username et email) pour garantir la validité des informations stockées.
---------------------------------------------------
-- Créer la table des utilisateurs
---------------------------------------------------
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL UNIQUE,
password VARCHAR(250) NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP
);
---------------------------------------------------
-- Créer la table des connexions entre utilisateurs
---------------------------------------------------
CREATE TABLE IF NOT EXISTS relationships (
requester_id INTEGER REFERENCES users(id) ON DELETE CASCADE,
receiver_id INTEGER REFERENCES users(id) ON DELETE CASCADE,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
validated_at TIMESTAMP,
PRIMARY KEY (requester_id, receiver_id)
);
---------------------------------------------------
-- Créer la table des comptes
---------------------------------------------------
CREATE TABLE IF NOT EXISTS accounts (
user_id INTEGER PRIMARY KEY REFERENCES users(id) ON DELETE CASCADE,
balance NUMERIC(15, 2) DEFAULT 0.00
);
---------------------------------------------------
-- Créer la table des transactions
---------------------------------------------------
CREATE TABLE IF NOT EXISTS transactions (
id SERIAL PRIMARY KEY,
sender_id INTEGER REFERENCES users(id) ON DELETE SET NULL,
receiver_id INTEGER REFERENCES users(id) ON DELETE SET NULL,
amount NUMERIC(15, 2) NOT NULL CHECK (amount > 0),
description VARCHAR(250),
processed_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP
);Points notables :
- La clef primaire de la table relationships est composée des ID du demandeur et du destinataire, garantissant qu’une relation ne peut être créée qu’une seule fois entre deux utilisateurs. Cette clé composite assure l’unicité des relations.
- La clef primaire de la table accounts est l’ID de l’utilisateur, ce qui garantit qu’un utilisateur ne peut avoir qu’un seul compte.
Focus sur l’optimisation SQL
Durant le développement de l’application, j’ai eu l’occasion d’explorer plusieurs techniques d’optimisation SQL pour améliorer les performances. Voici quelques-unes des techniques que j’ai mises en œuvre :
Les triggers
Durant la phase de développement de l’application, je me suis posé la question de savoir si SQL ne pouvait pas gérer lui-même la création d’un compte utilisateur après son inscription. Se dispenser de l’intermédiaire Java pour cette tâche me semblait être une solution plus élégante et plus performante.
C’est donc à cette occasion que j’ai découvert et décidé d’explorer les triggers SQL pour automatiser cette tâche.
Les triggers SQL sont des procédures stockées qui sont automatiquement exécutées en réponse à certains événements sur une table. Ils permettent notamment de réaliser des actions supplémentaires lors de l’insertion, de la mise à jour ou de la suppression de données.
En PostgreSQL, j’ai donc mis en place le trigger suivant :
---------------------------------------------------
-- Création de la fonction pour créer un compte après l'insertion d'un utilisateur
---------------------------------------------------
CREATE OR REPLACE FUNCTION create_account_after_user_insert()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO accounts (user_id)
VALUES (NEW.id);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
---------------------------------------------------
-- Création du trigger pour créer un compte après l'insertion d'un utilisateur
---------------------------------------------------
CREATE TRIGGER after_user_insert
AFTER INSERT ON users
FOR EACH ROW
EXECUTE FUNCTION create_account_after_user_insert();Avant toute chose, on définit la fonction qui sera utilisée par un trigger et qui retourne un TRIGGER. La fonction commence par BEGIN et se termine par END, avec les délimiteurs $$ pour le code PL/pgSQL et la spécification du langage utilisé, ici plpgsql.
Cette fonction a pour but d’insérer une nouvelle ligne dans la table accounts avec l’ID de l’utilisateur fraîchement créé. La variable spéciale NEW est utilisée pour accéder à la ligne qui vient d’être insérée dans la table users. Elle contient toutes les colonnes de cette nouvelle ligne, y compris l’ID de l’utilisateur, que nous récupérons pour créer automatiquement une entrée dans la table accounts. Enfin, la fonction renvoie la ligne insérée en utilisant RETURN NEW.
Le trigger associé, appelé after_user_insert, est déclenché après une insertion (AFTER INSERT) dans la table users et pour chaque nouvel enregistrement (FOR EACH ROW).
En parrallèle de ce trigger, j’en ai réalisé deux autres pour couvrir l’insertion de la date de modification d’un utilisateur, ainsi que le débit et le crédit sur les comptes concernés lors d’une transaction.
Cette approche m’a permis de réduire la complexité de mon code Java en déléguant certaines responsabilités à la base de données. Elle garantit aussi la cohérence des données, puisque les triggers sont automatiquement encapsulés dans une transaction SQL. Par exemple, si l’insertion d’un utilisateur échoue, l’insertion du compte associé sera annulée.
Enfin, cette solution améliore les performances de l’application en réduisant le nombre d’appels supplémentaires à la base de données.
Les projections
Dans le cadre de l’optimisation des performances des applications, il est crucial de réduire la quantité de données transférées entre la base de données et l’application. C’est pourquoi, à chaque fois que je travaille sur un projet avec une base de données, j’essaie d’optimiser au maximum les requêtes SQL. Pour cela, j’ai opté pour les projections SQL plutôt que de me reposer uniquement sur les fonctionnalités de Spring Data JPA, qui peuvent parfois être limitées.
Les projections SQL permettent de sélectionner un sous-ensemble de colonnes d’une table ou d’une vue, évitant ainsi le chargement complet des entités. Cela contribue à améliorer les performances globales de l’application.
Voici un exemple de projection SQL utilisée pour récupérer les relations d’un utilisateur :
public interface UserRelationshipProjection {
long getId();
String getUsername();
}Cette interface définit les attributs que je souhaite récupérer. J’ai utilisé cette interface dans une méthode de mon repository pour interroger les relations d’un utilisateur, en précisant des alias pour réaliser la correspondance entre les attributs de l’interface et les colonnes de la table :
@Query("SELECT u.id as id, u.username as username FROM User u " +
"JOIN Relationship r ON (r.id.requester = u OR r.id.receiver = u) " +
"WHERE (r.id.requester.id = :userId OR r.id.receiver.id = :userId) " +
"AND u.id <> :userId AND r.validatedAt IS NOT NULL")
List<UserRelationshipProjection> findUserRelations(@Param("userId") long userId);Avec JPA, il faut utiliser l’annotation @Query pour définir une requête SQL personnalisée. Dans cet exemple, je SELECT les colonnes id et username de la table User en les renommant respectivement id et username pour correspondre aux attributs de l’interface UserRelationshipProjection.
Ensuite, je JOIN la table Relationship pour récupérer les relations de l’utilisateur puisque cette information est stockée dans une table intermédiaire. ON (r.id.requester = u OR r.id.receiver = u) permet de lier les utilisateurs à leurs relations, en vérifiant si l’utilisateur est soit le demandeur, soit le destinataire de la relation.
La clause WHERE filtre les relations :
r.id.requester.id = :userId OR r.id.receiver.id = :userIdvérifie si l’utilisateur est soit le demandeur, soit le destinataire de la relation.u.id <> :userIdexclut l’utilisateur connecté de la liste des relations.r.validatedAt IS NOT NULLfiltre les relations validées, car seules les relations validées sont affichées.
Il convient de noter qu’il n’est pas toujours nécessaire de rédiger une requête SQL pour chaque projection. Spring Data JPA peut générer automatiquement les requêtes à partir des noms de méthodes, mais pour des cas complexes, la rédaction explicite de la requête devient nécessaire.
En outre, l’utilisation de vues SQL peut offrir une flexibilité supplémentaire pour définir des projections de données indépendamment de la structure de la base de données. Bien que cela puisse présenter des défis lors de la migration entre systèmes de base de données, des solutions telles que l’API Criteria permettent de générer des requêtes dynamiques sans écrire de SQL directement.
Les tests
Pour ce projet, j’ai mis en place des tests d’intégration qui ont permis de valider le comportement des services, des contrôleurs et des repositories, et de s’assurer que les fonctionnalités clés de l’application étaient correctement implémentées. J’ai utilisé JUnit pour écrire ces tests, en m’assurant de couvrir un maximum de cas d’utilisation pour garantir la robustesse de l’application, donc en traitant les cas normaux, les cas limites et les cas d’erreurs.
Cette approche m’a permis de découvrir une faille dans ma requête SQL pour la gestion des transactions. Le test passait pour les relations non existantes, ce qui signifie que les transactions n’étaient pas possibles entre utilisateurs qui ne s’étaient pas ajoutés en amis. Cependant, il était possible de réaliser une transaction entre deux utilisateurs en attente de validation de leur relation. Pour résoudre ce problème, j’ai appliqué un correctif consistant à encapsuler certaines conditions dans la requête SQL afin d’exclure ces cas.
@ParameterizedTest
@ValueSource(longs = {3, 6})
@DisplayName("Ajout d'une transaction - échec (destinataire non en relation ou en attente)")
public void registerTransactionFailureNoRelationship(long receiverId) {
transaction.getReceiver().setId(receiverId);
assertThrows(TransactionsException.class, () -> transactionService.registerTransaction(userSession, transaction));
}Ce test paramétré vérifie que l’ajout d’une transaction échoue lorsque le destinataire n’est pas en relation validée avec l’utilisateur connecté ou si la relation est en attente de validation. J’utilise l’annotation @ParameterizedTest pour exécuter le même test avec plusieurs valeurs d’ID de destinataire, en les passant via @ValueSource. Cette approche permet de réutiliser le même test pour différents scénarios sans répétition.
Dans ce cas, les valeurs passées (3 et 6) représentent deux situations distinctes :
- ID 3 correspond à un utilisateur qui n’est pas en relation avec l’utilisateur connecté.
- ID 6 représente un utilisateur dont la relation est en attente de validation.
Le test se déclenche avec chacune de ces valeurs, et la méthode registerTransactionFailureNoRelationship reçoit l’ID du destinataire. Ensuite, la méthode assertThrows(TransactionsException.class) vérifie qu’une exception de type TransactionsException est bien levée lorsque l’ajout de la transaction échoue, ce qui garantit que seules les transactions entre utilisateurs en relation validée sont autorisées.
Bien que l’application soit conçue pour empêcher de tels cas via un sélecteur contrôlé, ce test permet de couvrir d’éventuels contournements, comme la modification du code dans l’inspecteur de navigateur. Cela garantit la robustesse du système, même face à des manipulations malveillantes du côté client.
La requête qui posait problème est la suivante. Elle permet de vérifier si une relation est validée entre deux utilisateurs avant d’autoriser une transaction, mais elle ne fonctionnait pas comme attendu et il a fallut que j’englobe la première partie de la condition dans des parenthèses et la dissocier du dernier AND pour obtenir le résultat souhaité.
@Query("SELECT CASE WHEN COUNT(r) > 0 THEN TRUE ELSE FALSE END " +
"FROM Relationship r " +
"WHERE ((r.id.requester.id = :receiverId AND r.id.receiver.id = :userId) OR (r.id.requester.id = :userId AND r.id.receiver.id = :receiverId)) AND r.validatedAt IS NOT NULL")
boolean existsByUserIdAndReceiverId(@Param("userId") long userId, @Param("receiverId") long receiverId);La requête SQL vérifie si une relation validée existe entre l’utilisateur connecté et le destinataire de la transaction. Pour cela, elle compte (COUNT) le nombre de relations validées entre les deux utilisateurs. Si ce nombre est supérieur à zéro, la méthode renvoie TRUE, sinon FALSE.
La condition principale est définie par ((r.id.requester.id = :receiverId AND r.id.receiver.id = :userId) OR (r.id.requester.id = :userId AND r.id.receiver.id = :receiverId)). Elle vérifie si une relation existe entre les deux utilisateurs, peu importe qui est le demandeur et qui est le destinataire.
La clause AND r.validatedAt IS NOT NULL filtre les relations validées.
La couverture de code globale estimé par JaCoCo est de :
92%